Impress.js
29 September, 2014
One of the guys was trying this out the other day as an alternative to normal slide decks - looks fun.

Living in London, working with a lot of data.
Email will at cubittsmith dot co dot uk

One of the guys was trying this out the other day as an alternative to normal slide decks - looks fun.
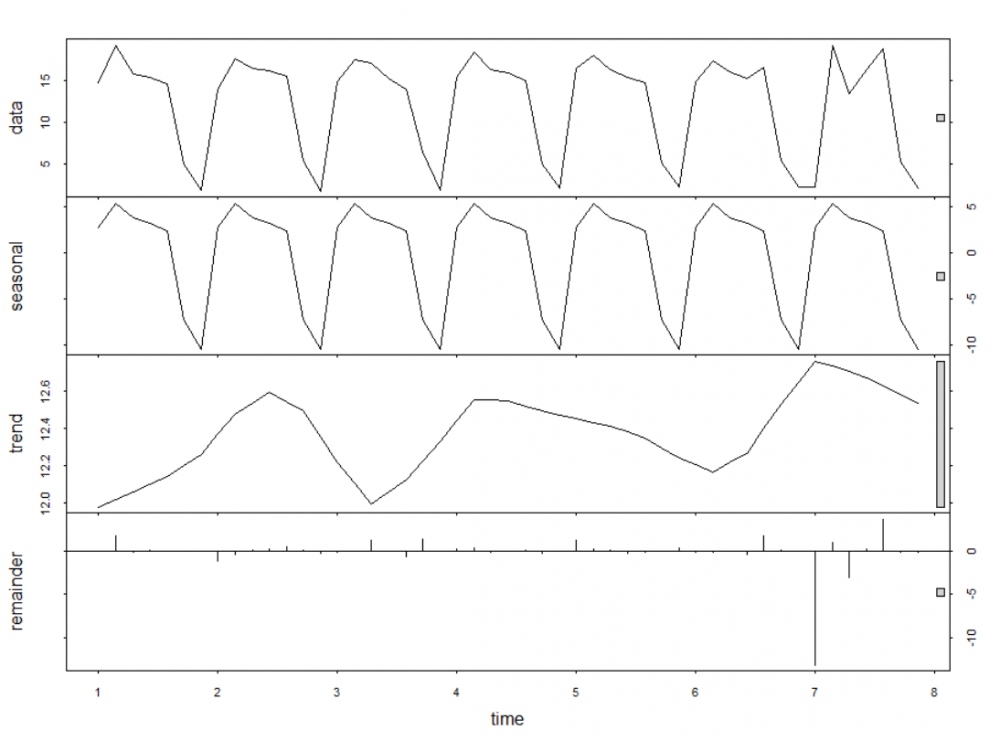
Recently I've been having fun with time series decomposition, and in particular, finding outliers in a particular time series.
To use a potentially weak analogy, let's say we're running a website, and we're looking for occasions when our users don't log on when they normally would. This method will help identify such occasions so they can be scrutinised!
Click permalink below to read more
Always a great fallback tool when you get ugly flat files. Recently I received 45 500mb flat files. Each one had a 5 lines of headers, with the row names on the fourth line. I used the following to build a single file with a 1 line header:
# Get the row names and put them in a new file called combined.csv
head -4 firstFile.txt | tail -1 > combined.csv
# Get the data from all files and append to combined.csv
# The more complicated 'find, while, do, done' is there because my file names had spaces in
find ./*.txt | while read file; do awk 'NR>5' "$file"; done >> combined.csv
# Finally do a row count reconcilisation
wc -l *.txt && wc -l combined.csv
Ever wanted to mine the entire global address book and then present it as an interactive visualisation?
Me too!
First off, we need the data. The following VBA code can be run in Outlook to iterate through the whole address book and pull the data. The key fields here are really the alias and the manager - that's how we're going to build our hierarchy.
Click permalink below to see more
I've been having a play with twitter sourced wordclouds this afternoon. Here's one I made with the search term 'Jeremy Clarkson':
Click permalink below to see a few more, and find out how I made them!